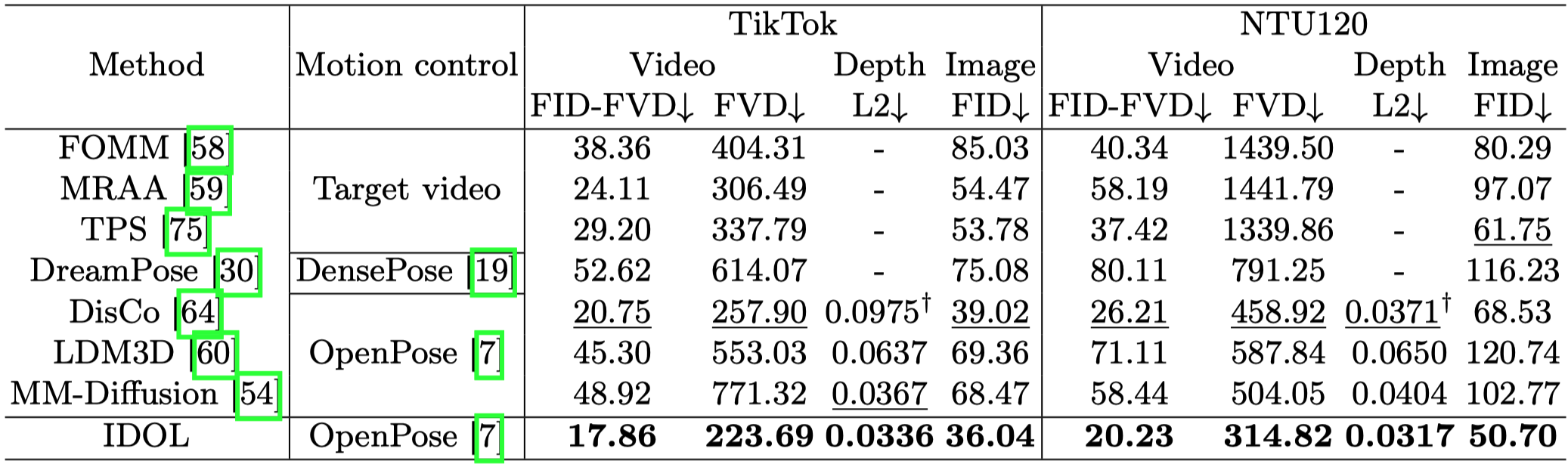
Method
Unified dual-modal U-Net
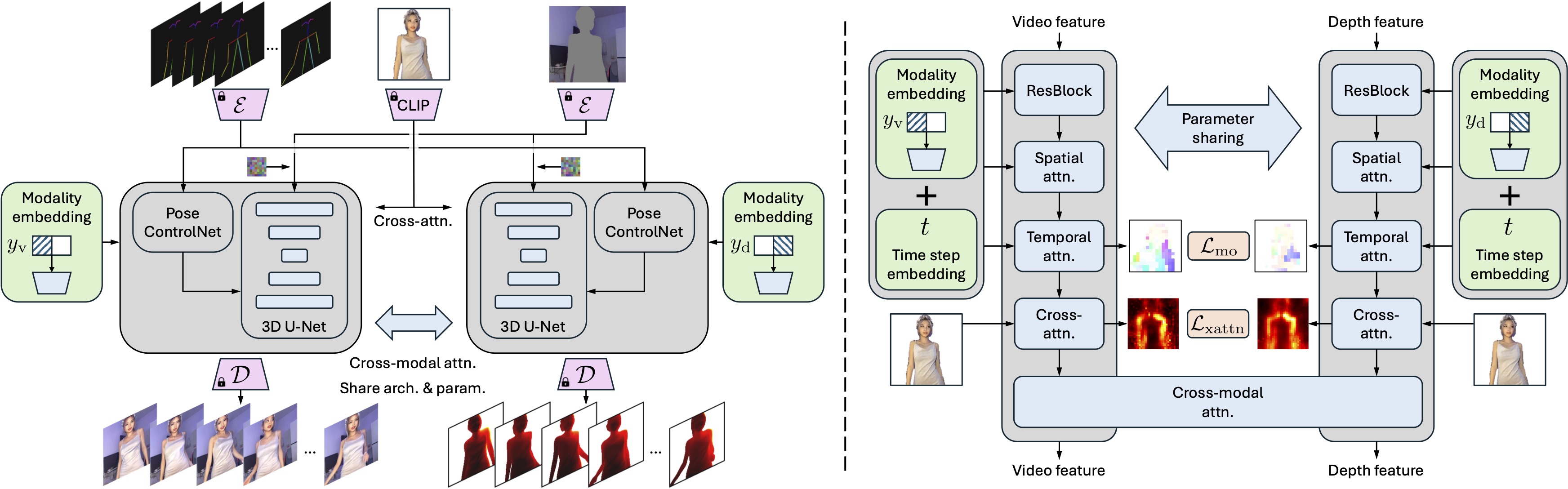
Left: Overall model architecture. Our IDOL features a unified dual-modal U-Net (gray boxes), a parameter-sharing design for joint video-depth denoising, wherein the denoising target is controlled by a one-hot modality label (\(y_{\text{v}}\) for video and \(y_\text{d}\) for depth).
Right: U-Net block structure. Cross-modal attention is added to enable mutual information flow between video and depth features, with consistency loss terms \(\mathcal{L}_{\text{mo}}\) and \(\mathcal{L}_{\text{xattn}}\) ensuring the video-depth alignment. Skip connections are omitted for conciseness.
Learning video-depth consistency
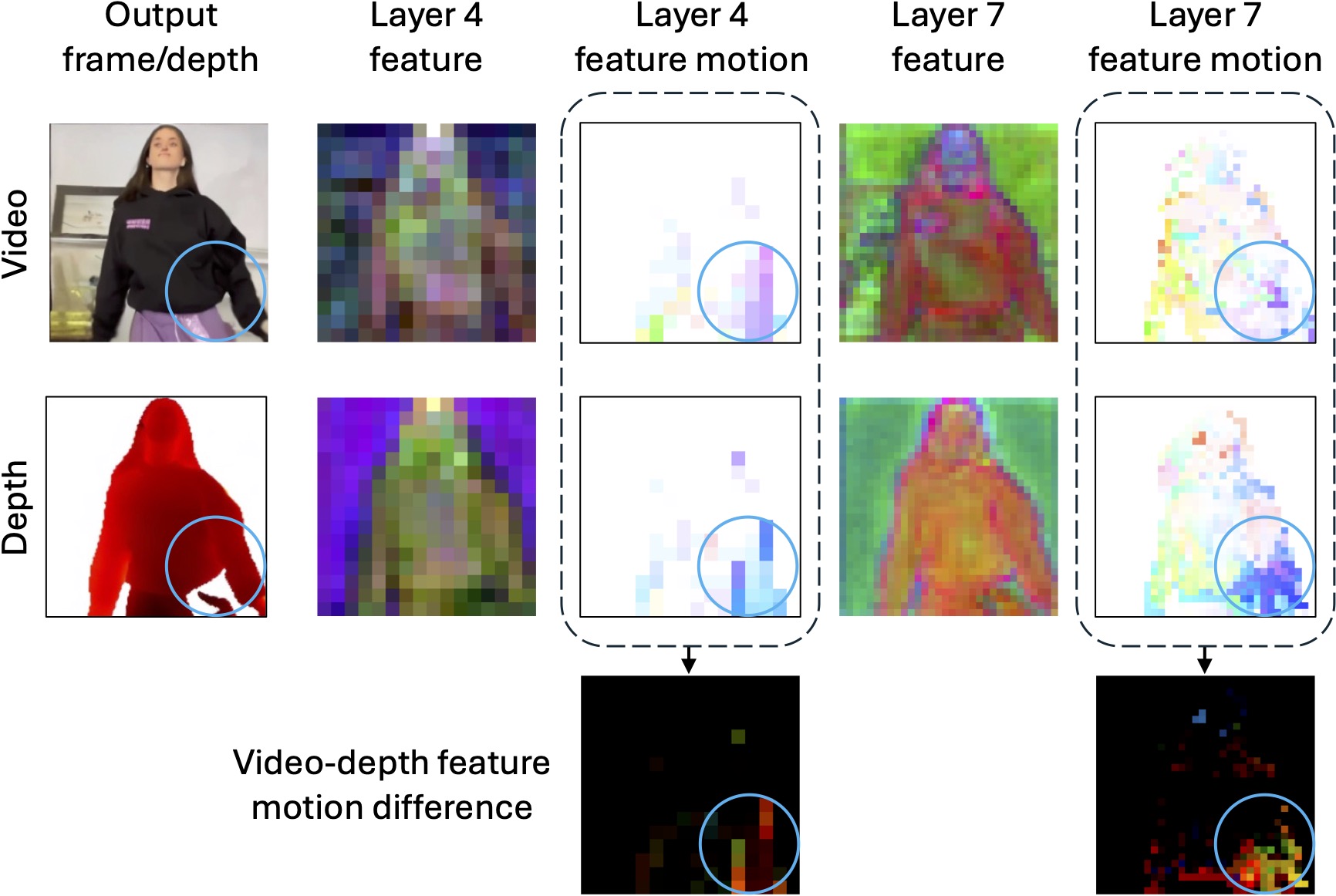
Visualization of the video and depth feature maps and their motion fields without consistency losses. We attribute the inconsistent video-depth output (blue circle) to the inconsistent video-depth feature motions (the last row). This problem exists in multiples layers within the U-Net, and we randomly select layer 4 and 7 in the up block for visualization. For the feature map visualization, we follow Plug-and-Play to apply PCA on the video and depth features at each individual layers, and render the first three components. The motion field is visualized similar to optical flow, where different color indicates different moving direction.
To promote video-depth consistency, we propose a motion consistency loss \(\mathcal{L}_{\text{mo}}\) to synchronize the video and depth feature motions, and a cross-attention map consistency loss \(\mathcal{L}_{\text{xattn}}\) to align the cross-attention map of the video denoising with that of the depth denoising.